A marketing analyst receives a new contact list every Monday morning. Before she can use it for the week's campaigns, she manually checks the email column for format errors, looks for duplicates, and scans for missing required fields. This takes 2–3 hours every week. Automated profiling does the same thing in 30 seconds.
This isn't hypothetical — it's the standard difference between manual and automated data profiling. And the time savings compound across every person and team that handles data files regularly.
What Manual Profiling Actually Involves
When someone "checks" a dataset manually, they typically:
- Scroll through the file looking for obvious problems
- Apply COUNTBLANK formulas to check completeness for key columns
- Use Remove Duplicates to find and count duplicate emails
- Filter for unexpected values in categorical columns
- Apply MIN/MAX formulas to numeric columns to check for outliers
Sohovi automatically finds every duplicate in your dataset — including near-matches — and shows you exactly which rows are affected.
For a 10,000-row CSV with 20 columns, doing this thoroughly takes 1–3 hours depending on experience. For a 100,000-row file, it's often not done at all — the analyst makes assumptions and proceeds.
What Automated Profiling Does
An automated profiling tool processes the same file in seconds or minutes and produces:
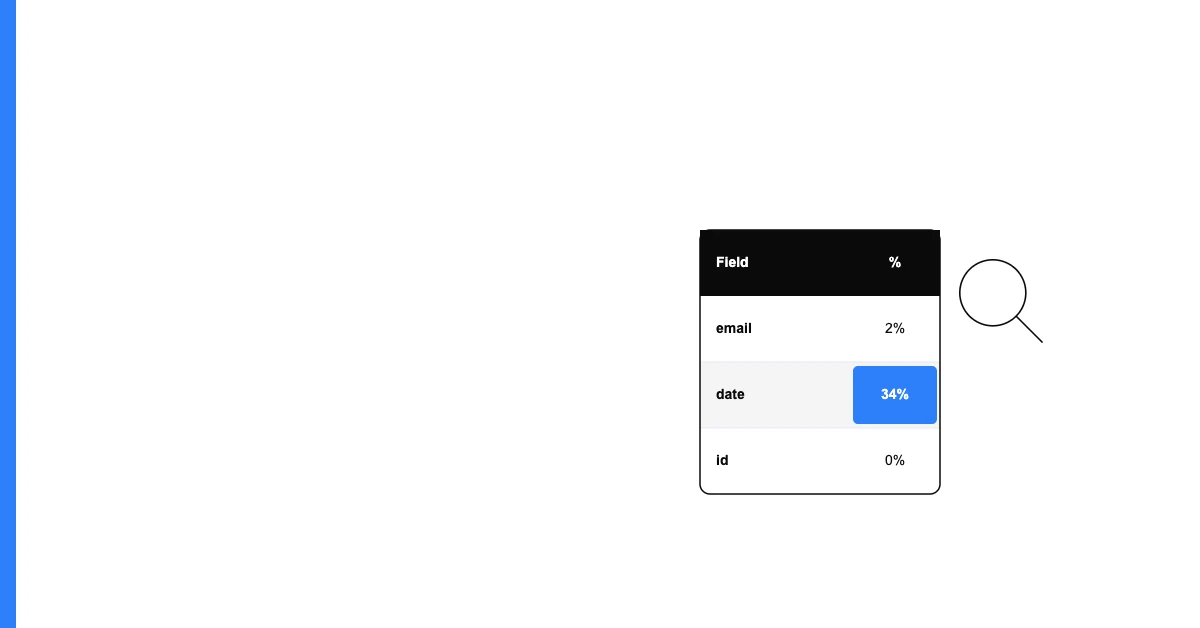
- Completeness rate for every column (not just the ones you thought to check)
- Uniqueness score for every column (not just the ones you expected to be unique)
- Format pattern analysis for every column (catching issues you didn't know to look for)
- Distribution analysis showing top values and distinct value counts
- PII detection across all columns
- Outlier flagging for numeric and date columns
Sohovi profiles every column in your dataset for completeness and flags the exact rows where values are missing — free to try.
The coverage is complete rather than sampled, and the speed is measured in seconds rather than hours.
The Hidden Cost of Manual Profiling
The time cost is obvious. Less obvious is the coverage gap. Manual profiling is selective — analysts check the columns they expect to be problematic. Automated profiling is comprehensive — it checks every column for every type of issue.
Industry estimates suggest analysts spend 20–40% of their time on data preparation and quality checks (Gartner). Automated profiling eliminates a large portion of that overhead.
Sohovi applies your data quality rules automatically across the whole dataset and highlights every violation — so nothing slips through.
When Automated Profiling Pays Off Most
- High-frequency use cases (weekly list imports, daily exports)
- Large files (50,000+ rows where manual checking is impractical)
- Multi-source merges (when combining data from multiple systems)
- Compliance-sensitive data (where completeness must be documented)
Try Sohovi free at sohovi.com — upload any CSV and get a complete automated profile in seconds. No setup, no code, no IT team needed. The time you save on the first file usually justifies the switch immediately.